
Presentation: Deep Deterministic Policy Gradient based Cooperative Platoon Logitudinal Control Strategy
Date:
Note: This work was reviewed and recommended for presentation at the TRB Annual Meeting 2021 by the TRB committee, not presented due to COVID-19
- Abstract:
This work presents a deep reinforcement learning (DRL) approach for vehicle platoon control in highways, addressing two key challenges: continuous precise control and string stability. We develop a DRL strategy that optimizes spacing, velocity, and acceleration through:- A multi-objective reward function balancing spacing error, velocity deviation, and acceleration limits
- A Deep Deterministic Policy Gradient (DDPG) algorithm combining actor-critic and deep Q-learning for continuous state-action control
- Validation showing comparable accuracy to distributed MPC, with faster response
Simulations demonstrate superior learning effectiveness, control precision, and platoon stability – advancing next-gen transportation systems through AI-driven automation.
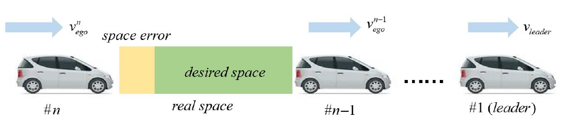
- Methods:
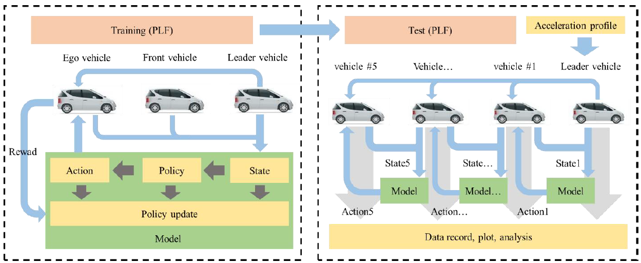
We proposed two training frameworks for two communication topologies: predecessor following (PF) and predecessor-leader following (PLF)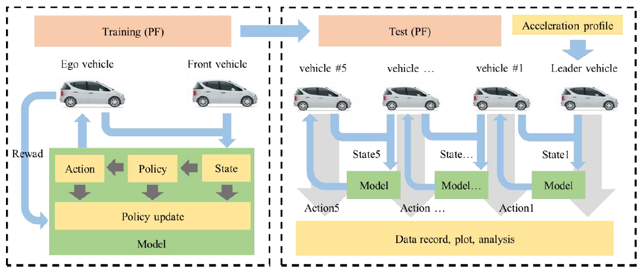
- Results:
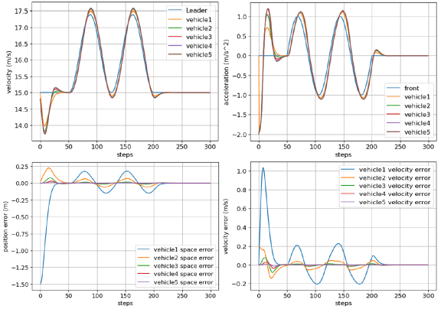
We applied the proposed methods to PF and PLF, and compared the Velocity, acceleration, space error, and velocity error of PF and PLF topology.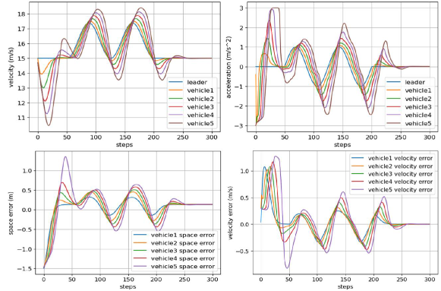
- Download:
The paper can be downded here